
What is Autoscaling?
Kubernetes autoscaling is a powerful feature that enables clusters to automatically adjust resources in response to changing demand, optimizing both performance and cost. It ensures applications have the right resources at the right time by dynamically scaling nodes or pods, based on real-time metrics. Kubernetes supports three key types of autoscaling:
1. Horizontal Pod Autoscaler (HPA) scales the number of pod replicas to meet workload demands.
2. Vertical Pod Autoscaler (VPA) fine-tunes the CPU and memory allocation for each pod to ensure optimal resource usage.
3. Cluster Autoscaling adjusts the number of nodes in the cluster to maintain efficiency and cost-effectiveness.
These autoscaling mechanisms work together to deliver elastic scalability, balancing reliability with cost efficiency. However, implementing autoscaling effectively requires addressing challenges such as balancing cluster response times, setting appropriate scaling triggers, and ensuring that horizontal and vertical scaling strategies are harmonized to avoid conflicts.
Kubernetes autoscaling empowers organizations to maintain high service availability while minimizing resource waste, making it an essential tool for modern cloud-native environments.
3 Kubernetes Autoscaling Methods
Horizontal Pod Autoscaler (HPA)
The Horizontal Pod Autoscaler (HPA) in Kubernetes dynamically adjusts the number of pod replicas in response to changing workload demands, ensuring optimal resource utilization and application performance. HPA continuously monitors real-time metrics such as CPU and memory usage, using the Kubernetes metrics server to assess whether scaling actions are needed.
If a defined threshold is crossed—such as CPU usage exceeding 70%—HPA will automatically increase or decrease the number of pods to meet the target value, ensuring efficient workload handling.
While typically focused on CPU and memory, HPA can also leverage custom or external metrics like network traffic or the number of pending tasks in a queue, enabling more tailored scaling strategies. It is particularly well-suited for stateless applications but can also manage scaling for stateful workloads.
Horizontal scaling enables rapid elastic capacity adjustments, making it essential for applications that experience unpredictable traffic spikes. However, it is not applicable to objects like DaemonSets that cannot be scaled. Combined with cluster autoscaling, HPA provides a powerful tool for balancing performance and cost efficiency in dynamic cloud environments.
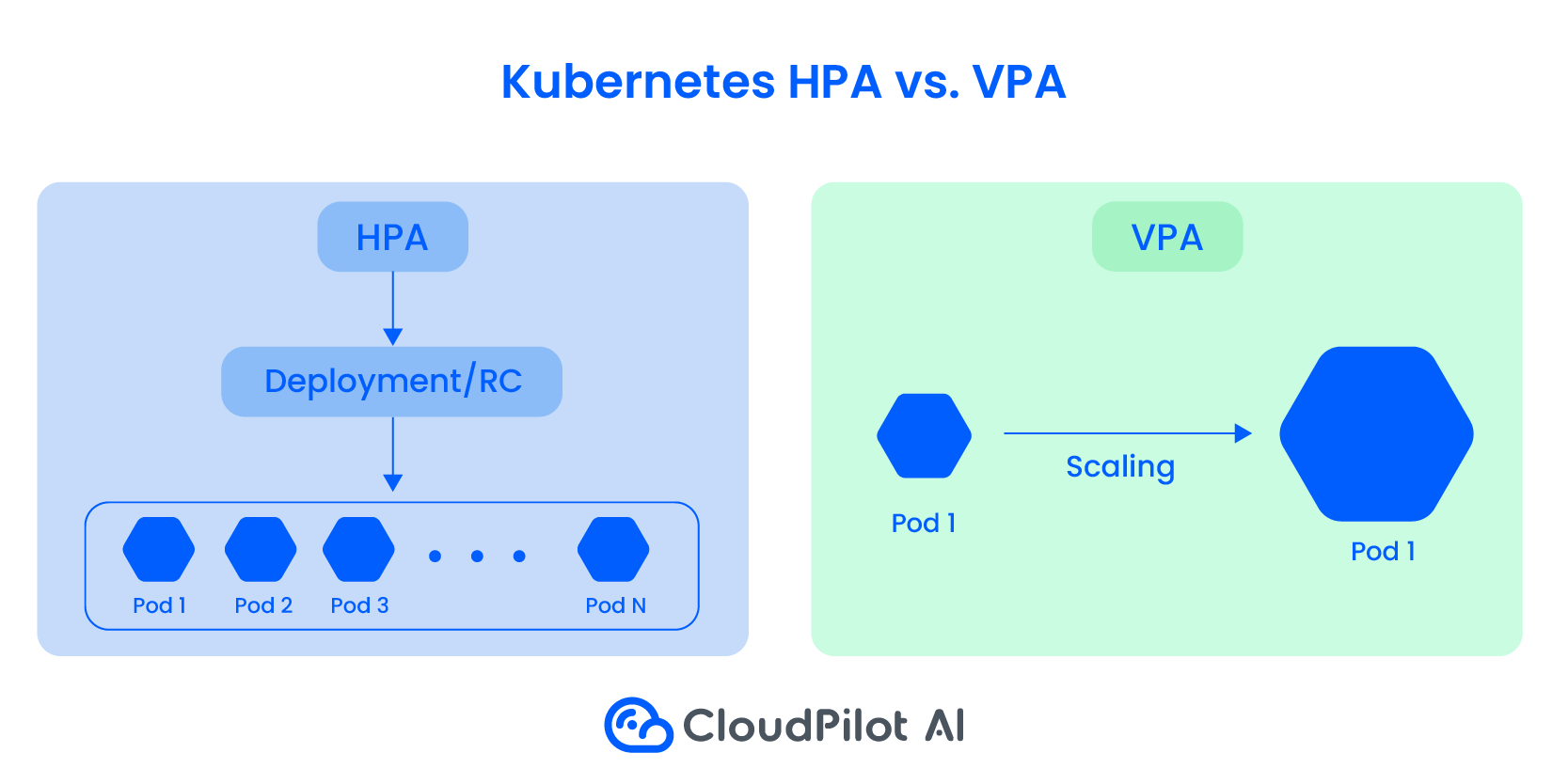
Vertical Pod Autoscaling(VPA)
The Vertical Pod Autoscaler (VPA) in Kubernetes automatically adjusts CPU and memory requests for pods to ensure that resource allocation matches actual usage.
Unlike the Horizontal Pod Autoscaler (HPA), which scales by adding or removing pods, VPA focuses on modifying the resource limits of individual pods. This is particularly useful for workloads that experience temporary spikes in resource demand or cannot be easily scaled horizontally.
VPA operates through three key components:
1. Recommender – Continuously monitors current and historical resource utilization to compute optimal resource limits.
2. Updater – Identifies pods running with outdated resource configurations and evicts them to apply the updated limits.
3. Admission Controller – Uses a mutating webhook to inject new resource requests into pods during their creation.
Since Kubernetes does not support changing resource limits for running pods, VPA terminates pods with outdated configurations, and when the pods are recreated by their controllers, they receive the updated limits. It can also run in "recommendation mode," where it suggests optimal resource values without terminating pods.
VPA is ideal for optimizing resource usage without wasting CPU or memory. However, when used alongside HPA, care must be taken to avoid conflicts, as both can influence resource allocation based on the same metrics. To achieve harmony, HPA can use custom metrics while VPA focuses on CPU and memory, enabling both autoscalers to work together effectively.
Cluster Autoscaling
Cluster Autoscaler (CA) in Kubernetes dynamically adjusts the number of nodes in a cluster to match the workload's resource requirements. It ensures efficient use of resources by adding nodes when pods cannot be scheduled due to insufficient CPU, memory, or mismatched taint tolerations and affinity rules.
Conversely, it removes underutilized nodes by rescheduling their pods onto other nodes when possible, considering pod priority and PodDisruptionBudgets.
The autoscaler continuously loops through two key tasks:
1. Scaling Up: Identifies unschedulable pods and checks if adding a new node would resolve the issue. If so, it increases the node pool size.
2. Scaling Down: Scans existing nodes for consolidation opportunities. If pods can be rescheduled elsewhere, the node is drained and terminated, allowing for a graceful termination period (typically 10 minutes) to ensure smooth rescheduling.
Cluster Autoscaler operates at the infrastructure level, requiring permissions to add or remove nodes. It is primarily used with cloud platforms and must be configured with secure credentials, adhering to the principle of least privilege.
By automating node scaling, CA optimizes costs and ensures sufficient capacity to handle workload demands, preventing overprovisioning while maintaining application reliability.
Another essential open-source tool to consider is Karpenter, an advanced cluster autoscaler alternative donated to CNCF in 2023. It supports AWS EKS, Microsoft Azure, and Alibaba Cloud AKS, with a mission to leverage cloud capabilities while remaining fast and simple to use.
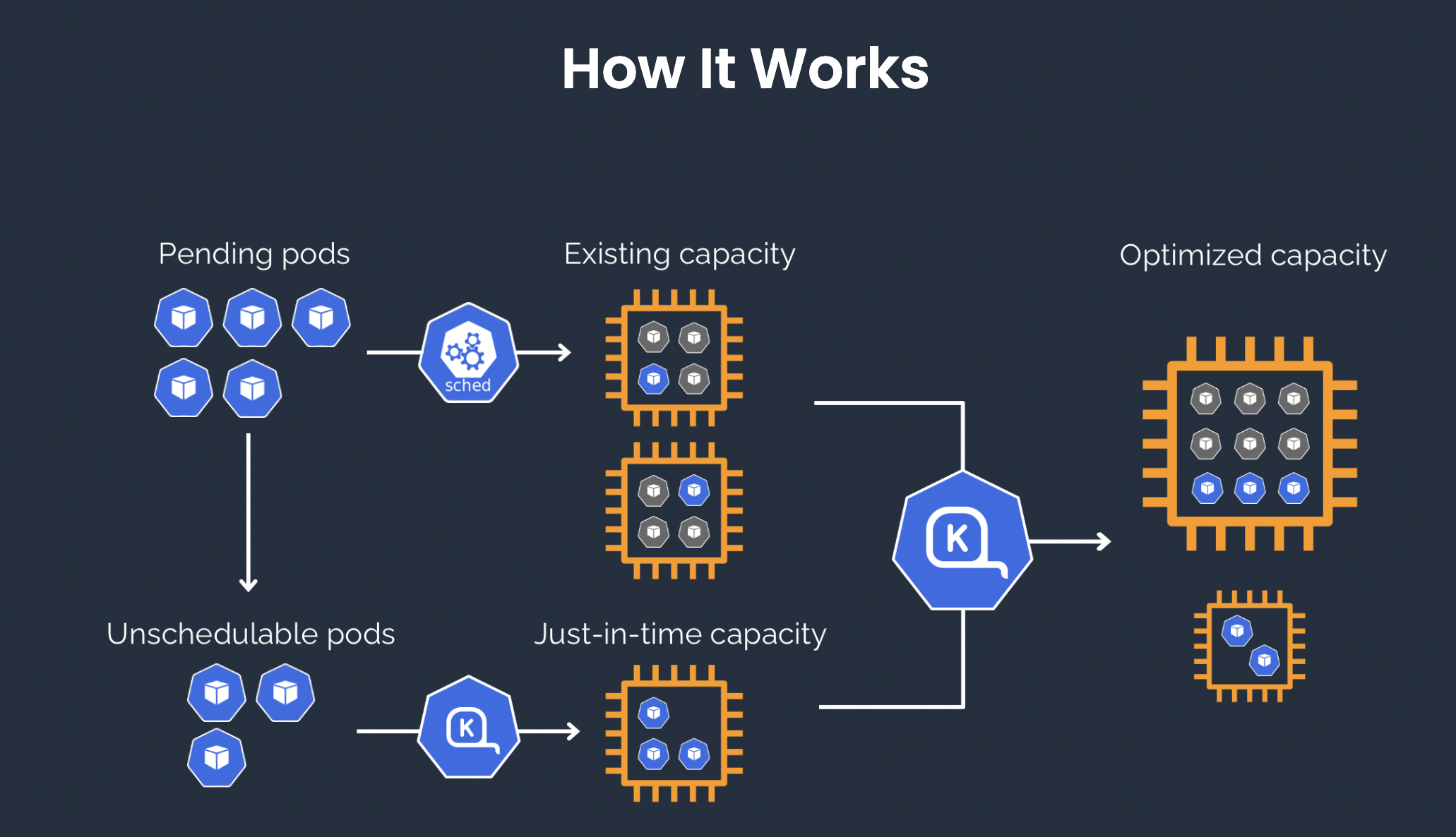
Karpenter’s innovative approach to cluster autoscaling enhances how Kubernetes clusters handle dynamic workloads by scaling faster and requiring less manual configuration for optimal results.
1. Proactive Node Management: Unlike traditional cluster autoscalers that depend on Auto Scaling Groups (ASGs) and can be slower to react, Karpenter directly manages nodes. This enables it to select the best instance types from hundreds of options and scale quickly without modifying ASGs. The result is faster, more efficient scaling in response to workload changes.
2. Intelligent Resource Consolidation: Karpenter identifies opportunities to reduce costs by optimizing the mix of node types. It consolidates resources by terminating underutilized nodes and replacing them with more efficient alternatives, ensuring the cluster uses every node effectively and matches resource supply with demand to minimize waste.
3. Spot Instance Optimization: Karpenter seamlessly integrates spot instances—temporary, lower-cost VMs—into the cluster. It strategically balances cost savings with the volatility of spot instance availability, expanding resources cost-effectively while maintaining performance and reliability.
Karpenter’s streamlined, automated approach delivers faster scaling, better resource utilization, and lower cloud costs, making it a powerful tool for dynamic Kubernetes environments.
Kuberentes Autoscaling Best practices
Here are 5 best practices for Kubernetes autoscaling to ensure efficient resource utilization, performance, and cost management:
1. Monitor and Analyze Resource Utilization:
Regularly monitor application performance metrics such as CPU, memory usage, and traffic patterns. This data is crucial for fine-tuning autoscaling thresholds to ensure optimal scaling behavior while avoiding unnecessary resource consumption.
2. Coordinate HPA and VPA Policies:
Ensure Horizontal Pod Autoscaler (HPA) and Vertical Pod Autoscaler (VPA) do not conflict. HPA scales the number of pods, while VPA adjusts resource requests for existing pods. Misalignment can cause unpredictable scaling behavior. Proper coordination ensures seamless scaling and optimal resource allocation.
3. Implement Mixed-Instance Strategies:
Use a combination of instance types (e.g., spot instances and on-demand instances) to reduce costs while maintaining availability. The Cluster Autoscaler can manage these diverse instances efficiently if they have compatible resource capacities, ensuring cost savings without compromising performance.
4. Handle Rapid Scaling Events:
Prepare for sudden spikes in demand by carefully tuning scaling policies and ensuring infrastructure can support rapid scaling. Setting appropriate resource limits, requests, and quotas ensures that autoscaling can respond quickly without compromising application stability.
5. Use Custom Metrics and Service Mesh:
Leverage custom metrics and service meshes like Istio or Envoy to enhance autoscaling decisions. Custom metrics (e.g., request rate or response time) provide more granular insights, allowing HPA to make informed scaling decisions. Service meshes also add resilience through load balancing, retries, and circuit breaking.
By following these practices, Kubernetes environments can achieve scalable, cost-efficient, and reliable application deployments.
Conclusion
In this blog, we looked at three ways of scaling Kubernetes: HPA, VPA, and cluster autoscaling. We also covered best practices for Kubernetes autoscaling. This blog gave you an overview of Kubernetes autoscaling to help beginners get a big picture of it. In the near future, we'll go deeper into this topic to share more insights, tools, and practices. Stay tuned!









